
Technology
At the highest level, Infinit is a storage platform that allows for creating storage infrastructure that are flexible, controlled, secure and natural to use.
However, at the technology level, Infinit is a set of independent layers that can be used to develop powerful applications, create block-level data stores and more.
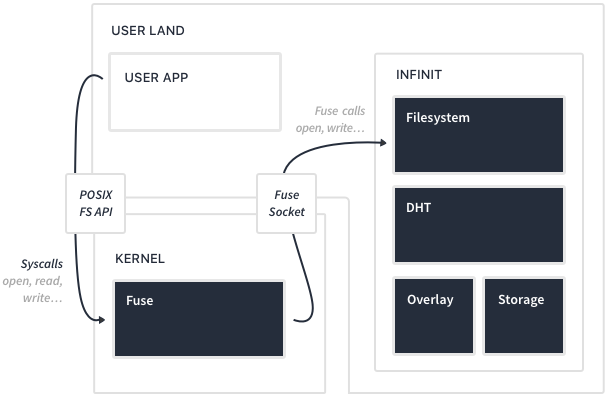
System calls issued by applications go through the kernel, back to the userspace through FUSE to finally reach Infinit software stack.
Elle
#high-performance #interoperability
The Elle library is a C++ development coroutine-based framework based the reactor pattern that allows for highly-concurrent and natural programming. What this means is that, unlike existing asynchronous frameworks that rely on threads and/or callbacks, Infinit’s reactor allows developers to write sequential code that is easy to write/read and therefore to maintain.
This layer is composed of modules to perform various operations such as HTTP calls, RPCs, dealing with NATs, serializing data, writing FSMs, performing cryptographic operations and many more, the whole asynchronously in order to be as efficient as possible.
Echo Server Example
In the Boost example, you will notice that there are a system of callbacks which quickly becomes confusing.
Boost Example (full code here)
....
void do_read()
{
auto self(shared_from_this());
socket_.async_read_some(boost::asio::buffer(data_, max_length),
[this, self](boost::system::error_code ec, std::size_t length)
{
if (!ec)
{
do_write(length);
}
});
}
void do_write(std::size_t length)
{
auto self(shared_from_this());
boost::asio::async_write(socket_, boost::asio::buffer(data_, length),
[this, self](boost::system::error_code ec, std::size_t /*length*/)
{
if (!ec)
{
do_read();
}
});
}
....
The Reactor example uses a coroutine with a while loop to accept connections from clients and then a coroutine for each client. The reading and writing to each client is handled again in a simple while loop.
Reactor Example (full code here)
...
void echo(std::shared_ptr<reactor::network::Socket> socket)
{
try
{
while (true)
{
elle::Buffer line = socket->read_until("\n");
socket->write(line);
}
}
catch (reactor::network::ConnectionClosed const&)
{}
}
...
Learn More
If you want to go further, check out our two presentations from our last C++ meetups.
![]() Highly concurrent yet natural programming
Highly concurrent yet natural programming
![]() Infinit filesystem, Reactor reloaded
Infinit filesystem, Reactor reloaded
Overlay Network
#control #affordable #scalable #fault-tolerant #migration
The overlay network layer connects the devices (desktop computer, server, mobile etc.) in a peer-to-peer manner i.e without a central server. The main purpose of this layer is to map identifiers (more precisely ranges of identifiers) onto nodes and to provide an algorithm to locate the node responsible for a given identifier.
Such a layer can be used for many different purposes from distributing jobs between computers (a node being responsible of as many identifiers as it has computing resources) to distributing data to archive etc.
There exists a large variety of overlay networks, some supporting very small networks but being extremely fast, others scaling to several million of nodes and other relying on more complicated algorithms to tolerate malicious nodes.
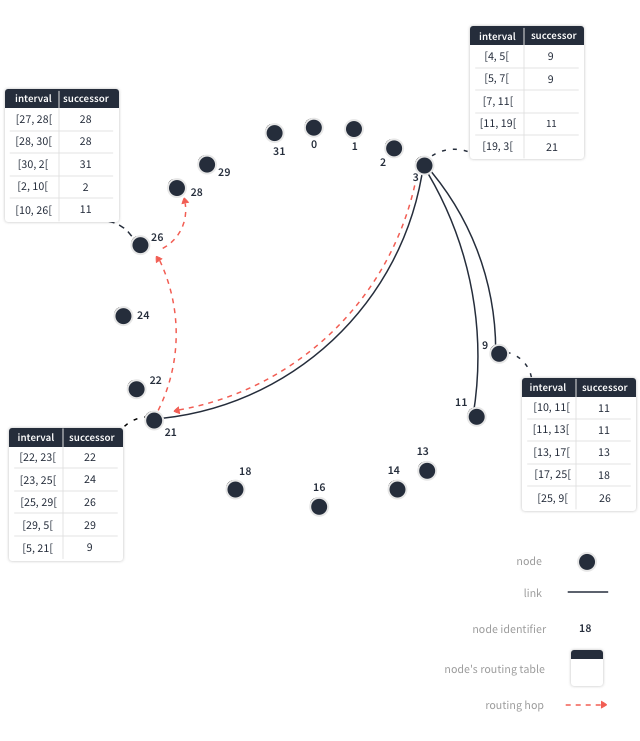
Caption: An illustration of the Chord overlay network.
The decentralized nature of the overlay network ensures scalability and performance while removing any bottleneck and single point of failure. In addition, such systems no longer need to rely on a complicated infrastructure composed of specific server hardware, appliances and ancient client software. The overlay naturally distribute the load between the nodes while tolerating faults.
Finally, by creating the overlay network according to your needs (data location for instance), you control the flow of information. Also, the flexibility to add and remove nodes dynamically makes such systems extremely affordable.
Distributed Hash Table
#flexible #reliable #migration
The distributed hash table (DHT) layer relies on the overlay network to provide a key-value store similar to hash tables, with the difference that the information is distributed across the network.
Even more than for the overlay network, the DHT construct can be, and has already been, used to develop many applications from web caching, content distribution, domain name service, instant messaging and more.
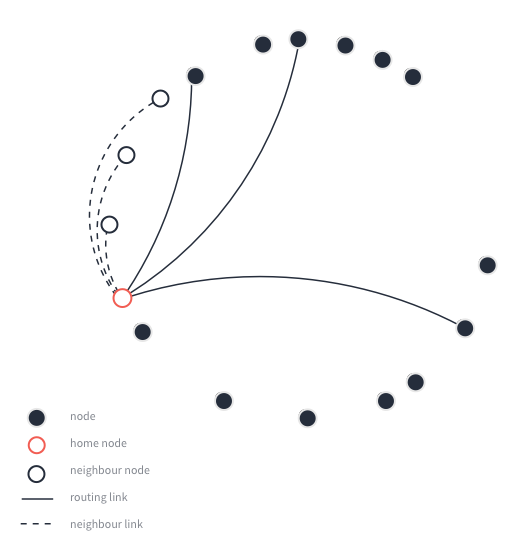
Caption: An example of DHT built on top of Chord and replicating the ‘value’ four times: once on the node responsible for the ‘key’ identifier and three more times on the neighbor nodes.
In addition to distributing the values among the nodes composing the overlay network, the DHT is responsible for replicating the items in order to ensure reliability and availability while providing an efficient way to retrieve the value given its key.
Note: In practice, the overlay network and distributed hash table are often combined into a single piece of software. For more information on the overlay networks and DHTs available, please refer to the reference documentation.
File System
#secure #natural #on-demand #access-control #versioning
The file system layer offers a hierarchical file organization on top of the distributed hash table whose role is to store blocks of data in a similar way to a hard disk.
Unlike many well-known services like Dropbox, Bittorrent’s Sync, Google Drive etc., Infinit provides a low-level native file system integration that abstracts the file system hierarchy through a virtual drive.
Dropbox for instance, once installed on a new device, downloads all the files from the cloud in order to create a mirror/clone locally. This mechanism unfortunately suffers from a major limitation: the files cloned locally consume storage space on the user’s device and incidentally, a user without enough available storage capacity will not be able to access a very very large Dropbox.
This is a big problem for businesses that need to create storage spaces to store a lot of data. Infinit on the other hand, does not require the files to be cloned locally. Rather, when a file is accessed, the blocks are retrieved from the DHT for the file to be reconstructed, partially or completely, depending on the system call. This also means that mounting an Infinit file system gives the user immediate access to all the hierarchy no matter the amount of data it contains.
Thanks to the on-demand property of the Infinit file system, developers and system administrators can create storage infrastructure of extremely large size that will be accessible on any device, no matter how much storage capacity they have left locally.
Note that one can configure a device to use a limited amount of local storage capacity to act as a cache, hence speeding up accesses. Likewise, one could want to keep some files or part of the file system hierarchy local at any time for offline access.
Another problem with most cloud storage providers is that the files are not encrypted, leaving the user with no choice but to trust the cloud storage provider. Infinit has been conceived with the assumption that no storage provider can be trusted. In addition to relying on fault-tolerant algorithms, Infinit makes use of strong encryption. Whenever a document is edited for instance, the file is cut into chunks, every chunk is encrypted and then distributed and replicated throughout the distributed hash table. Every key used for encrypting a block is unique and known to the file owner only (along with the users who have been granted access).

Finally, the file system layer also provides access control (without the use of a centralized server), versioning and other file-system-related features.

Talk to us on the Internet!
Ask questions to our team or our contributors, get involved in the project...