
Examples of Deployments
Infinit can be set up in a large variety of configurations, creating storage infrastructure with different tradeoffs between reliability, performance of access, cost, etc.
The following provides some examples of deployments along with the commands you would need to execute on the machines involved in the infrastructure. Hopefully, this will give you enough information to adapt the deployments according to your needs.
In order to keep things simple, the examples below follow the same pattern: Alice is the user that sets up the storage infrastructure. Alice accesses a volume from her device A while allowing Bob and other users to access it from their respective devices: B, C, etc.
Centralized (single server)
In this configuration, data is stored in a centralized location. Since there is a single server involved, the files are not replicated. The availability of the infrastructure is thus fully dependent on this single server and cannot be guaranteed. Should the server fail, all the files would be rendered inaccessible to the users; temporarily or permanently depending on the failure. This is referred to as having a single point of failure.
This durability/availability limitation can be avoided by adding more servers. However, you may want to set up such a storage infrastructure to store short-lived non-critical data for instance. Note that such a deployment is similar to what services such as OwnCloud, Pydio or a simple WebDAV service provide.
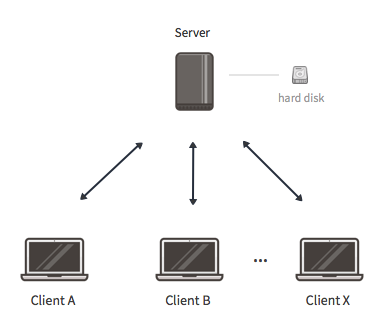
In order to set up such an infrastructure, please follow the instructions below, taking care to adjust the options according to your needs (storage capacity contributed by the server, names of the network/volumes etc.).
IMPORTANT: For Bob and subsequent users to be able to list/edit the volume's root directory, Alice needs to grant them access to do so through the infinit acl. Without this step, users would simply get a Permission Denied error.
$> infinit silo create filesystem --capacity 100GB --name local
$> infinit network create --as alice --storage local --replication-factor 1 --name cluster --push
$> infinit volume create --as alice --network cluster --name shared --push
$> infinit user fetch --as alice --name bob
$> infinit passport create --as alice --network cluster --user bob --push
$> infinit network run --as alice --name cluster --cache --publish
$> infinit network --fetch --as alice
$> infinit volume fetch --as alice
$> infinit network link --as alice --name cluster
$> infinit volume mount --as alice --name shared --cache --publish --mountpoint mnt/shared/
$> infinit user fetch --as bob --name alice
$> infinit network fetch --as bob
$> infinit volume fetch --as bob
$> infinit passport fetch --as bob
$> infinit network link --as bob --name alice/cluster
$> infinit volume mount --as bob --name alice/shared --cache --publish --mountpoint mnt/shared/
Download full shell script: ![]() centralized.sh.
centralized.sh.
Distributed (multiple servers)
This type of deployment is more reliable than the previous one as it relies on several servers to distribute the storage load so as to tolerate failures. In many ways, such a deployment is similar to other systems such as MooseFS, HDFS, XtreemFS and even Dropbox (with the servers reprensenting the underlying object store i.e. Amazon S3). Such systems are designed to scale within the boundaries of a trusted server infrastructure e.g. a controlled data center.
The main difference between this deployment and existing distributed storage systems is that the latter commonly rely on a set of specific servers referred to as master servers or metadata servers to control critical aspects of the infrastructure: location of the data blocks, access control, versioning, locking etc. Infinit on the other hand provides such functionalities through an architecture that does not require super-privileged master servers.
The main concern when it comes to this distributed deployment is to ensure that it is scaled according to the load of requests that will be generated by clients. If there are not enough servers, there will be a bottleneck serving the client requests. Should one of the servers fail, the problem would be exacerbated as clients redirect their requests to the other servers. This could lead to a cascading failure.
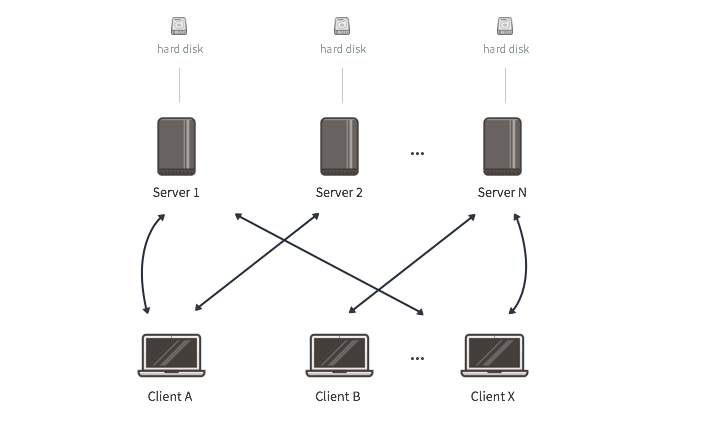
Follow the steps below to set up such an infrastructure. Note that a replication factor of 2 has been chosen but can be adapted according to your needs and the number of servers involved:
$> infinit silo create filesystem --capacity 20GB --name local
$> infinit network create --as alice --storage local --replication-factor 2 --name cluster --push
$> infinit volume create --as alice --network cluster --name shared --push
$> infinit user fetch --as alice --name bob
$> infinit passport create --as alice --network cluster --user bob --push
$> infinit network run --as alice --name cluster --cache --publish
$> infinit network --fetch --as alice
$> infinit silo create filesystem --capacity 50GB --name local
$> infinit network link --as alice --name cluster --storage local
$> infinit network run --as alice --name cluster --cache --publish
$> infinit network --fetch --as alice
$> infinit volume fetch --as alice
$> infinit network link --as alice --name cluster
$> infinit volume mount --as alice --name shared --cache --publish --mountpoint mnt/shared/
$> infinit user --fetch --as bob --name alice
$> infinit network fetch --as bob
$> infinit volume fetch --as bob
$> infinit passport fetch --as bob
$> infinit network link --as bob --name alice/cluster
$> infinit volume mount --as bob --name alice/shared --cache --publish --mountpoint mnt/shared/
Download full shell script: ![]() distributed.sh.
distributed.sh.
Decentralized (all servers)
This type of deployment addresses the limitations of the previous ones by distributing the storage load, hence the requests, between a large number of nodes. A large number of storage nodes can be achieved by making use of end-user devices and the unused storage that they have. These devices can serve other clients, effectively spreading the request load.
As a result, such a highly-scalable decentralized deployment can support a large number of clients. This approach also removes single points of failure and other bottlenecks. The scalable nature of such a deployment ensures fault tolerance as the system automatically detects failing servers and transparently rebalances the impacted blocks so as to maintain the replication factor.
Take note that the replication factor you define can drastically change the infrastructure's behavior. For instance, should you set the replication factor to equal the number of storage nodes in the network, all the blocks of all the files would be replicated on every machine acting as a server (i.e. contributing storage capacity). Such a configuration would be equivalent to Bitorrent Sync. Even though having all the files on your machine at any time is interesting for accessibility, it also consumes a lot of storage capacity on every user's computer.
Ideally, a replication factor high enough for all the files to be available even if some of the nodes are turned off (without requiring all the computers to store a replica for all the files) should be preferred. A higher volatility of the nodes would require a higher factor of replication. Note, however, that the replication factor must never exceed the number of storage nodes in the storage infrastructure.
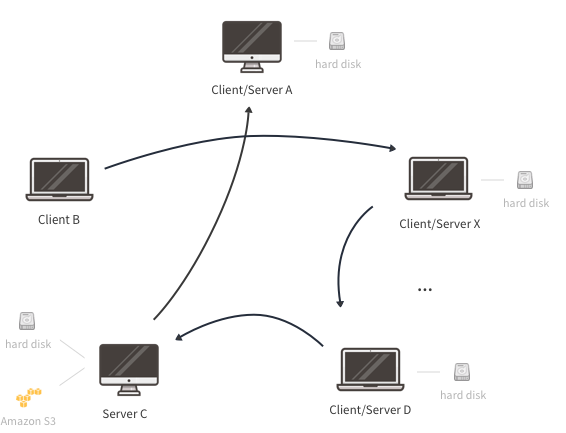
Follow the instructions below to set up such an infrastructure. Of note is that the example below is composed mostly of nodes contributing storage capacity from thier local disk while a machine (server C) contributes storage from both its local disk and a public cloud provider, in this case Amazon S3. In addition, while most devices (A, D ... X) contribute storage and access the volume, some nodes operate as a client or server only (B as a client and C as a server).
$> infinit silo create filesystem --capacity 15GB --name local
$> infinit network create --as alice --storage local --replication-factor 3 --name cluster --push
$> infinit volume create --as alice --network cluster --name shared --push
$> infinit user fetch --as alice --name bob
$> infinit user fetch --as alice --name charlie
$> infinit user fetch --as alice --name dave
$> infinit passport create --as alice --network cluster --user bob --push
$> infinit passport create --as alice --network cluster --user charlie --push
$> infinit passport create --as alice --network cluster --user dave --push
$> infinit volume mount --as alice --name shared --cache --publish --mountpoint mnt/shared/
$> infinit user fetch --as bob --name alice
$> infinit network fetch --as bob
$> infinit volume fetch --as bob
$> infinit passport fetch --as bob
$> infinit network link --as bob --name alice/cluster
$> infinit volume mount --as bob --name alice/shared --cache --publish --mountpoint mnt/shared/
$> infinit user --fetch --as charlie --name alice
$> infinit network fetch --as charlie
$> infinit volume fetch --as charlie
$> infinit passport fetch --as charlie
$> infinit silo create filesystem --capacity 30GB --name local
$> infinit credentials --add --as charlie --aws --account aws
Access Key ID: ********
Secret Access Key: ********
$> infinit silo create s3 --account aws --region eu-central-1 --bucket charlie --path alice.cluster --capacity 100GB --name s3
$> infinit network link --as charlie --name alice/cluster --storage local --storage s3
$> infinit network run --as charlie --name alice/cluster --cache --publish
$> infinit user fetch --as dave --name alice
$> infinit network fetch --as dave
$> infinit volume fetch --as dave
$> infinit passport fetch --as dave
$> infinit silo create filesystem --capacity 50GB --name local
$> infinit network link --as dave --name alice/cluster --storage local
$> infinit volume mount --as dave --name alice/shared --cache --publish --mountpoint mnt/shared/
Download full shell script: ![]() decentralized.sh.
decentralized.sh.

Talk to us on the Internet!
Ask questions to our team or our contributors, get involved in the project...