

Overview
memo can be considered as a key-value store in the same vein as etcd, ZooKeeper, Consul etc, allowing clients to store values and reference them through a user-selected key.
Unlike existing key-value stores, memo takes a radically different approach when it comes to data distribution, consistency and more, allowing for better scalability, performance, security and resilience. memo's approach is particularly appreciated from applications that need to scale to million of nodes, tolerate Byzantine failures, require extreme throughput etc.
Below are listed memo's high-level properties:
- Software: does away with hardware dependencies and can be deployed anywhere (bare metal, virtual machine, container etc.).
- Elastic: can scale up/down and out/in according to the needs of the overlying applications.
- Resilient: tolerates failures and can rebalance the impacted values to other nodes so as to maintain redundancy.
- Open Source: can be modified and improved by the community following the open source philosophy.
One of the major differentiator with existing systems is the fact that memo is fully customizable through policies. Through such policies, a developer or operator can configure the underlying data store to behave in a way that suits her application. While some will want to activate versioning and erasure coding for maximum safety, others may need to deactivate encryption to reduce the overhead and loosen the consistency model to increase write performance.
Layers
Also, unlike existing solutions that offer a straightforward key-value store application programmable interface (API), memo is in fact composed of two layers, each with its own API. As illustrated below, the key-value store is built on top of what is referred to as a value store.
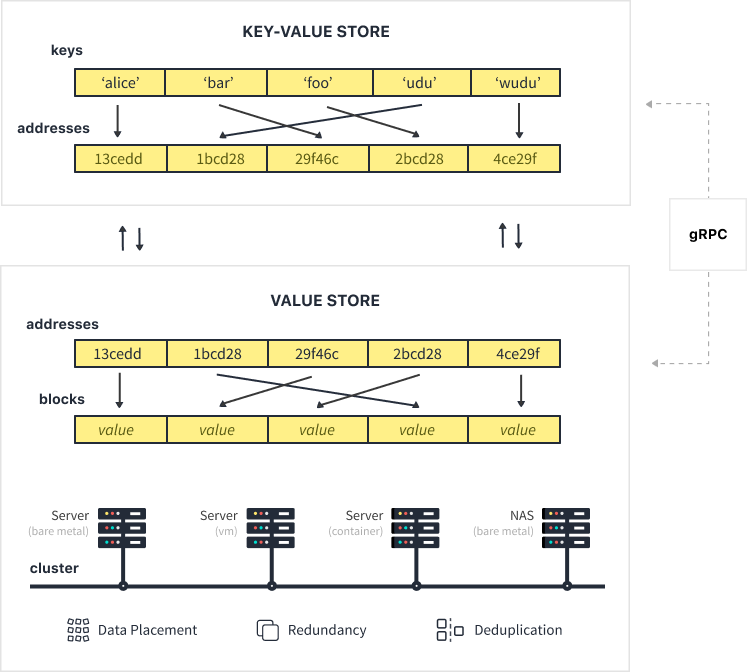
Value Store
The value store is the most fundamental layer, dealing with data distribution, consistency, fault tolerance, rebalancing and much more.
As its name suggests, this layer does away with the notion of key. Instead, a client inserts a piece of data --- referred to as a block --- and is returned an address for future reference. The reason behind not letting clients pick the address is for it to be randomly generated so as to optimize data placement, fault tolerance and more.
NOTE: Given its terminology, this layer could have been referred to as a "block store". Unfortunately, such a name would be too confusing with block storage a.k.a block devices.
The value store also differs from existing systems by introducing different types of blocks, each with tradeoffs. At the core of the value store lies two fundamental families of blocks: immutable and mutable blocks.
Mutable blocks, as the name suggests, can evolve over time. As such, there can be multiple versions of the same block. Clients could therefore conflict trying to update the same block at the same time, requiring a consensus algorithm to be run to maintain consistency between the servers hosting the block's replicas. Also, a client with a caching policy will need to invalide such blocks to refresh its cache from time to time by refeteching them from the value store.
Immutable blocks however can only exist in a single version. Even though it sounds constraining at first, this construct has a number of benefits. Since such blocks cannot be updated, there cannot be any conflict. Also, because memo's value store is content addressable, blocks are self-certified, meaning that blocks can be retrieved from any source (a distributed cache, a neighbor node or else) instead of contacting a quorum of servers hosting the block's replicas. Lastly, such blocks can be kept in cache forever because there cannot be a more recent version in the system.
Given such specificities, it is important for developers to perfectly understand the tradeoffs of those blocks in order to make good use of the value store. In practice, it is extremely common to use a mutable block as the entry point containing metadata information along with a list of addresses referencing immutable blocks used to store the actual data.
Key-Value Store
The key-value store provides an easy way for any developer to store a value by associating it with a key. This key allows one to reference the value later on, to fetch it, update it and more.
By using the key-value store, a developer does not have to remember the addresses of the blocks it inserted nor does she have to deal with the specificities of the value store, such as which type of block to use.
This ease-of-use however comes at a cost. Indeed, the key-value store maintains an index in order to map the user-picked keys to the addresses of the blocks holding the stored value. The key-value store therefore adds a level of indirection through this mapping data structure, potentially impacting performance (depending on the use case) compared to using the value store directly.
NOTE: When storing values through the key-value store's API, an immutable block (embedding the value) is created and stored through the value store's API. Then an entry is added to the mapping data structure so as to reference the block's address through the user-defined key. Data mutability is therefore achieved through the mapping data structure which can be updated. The value store however allows one to decide mutability for every block.
Conclusion
To summarize, the key-value store provides a simple set of gRPC functions to insert, update and delete values associated with keys while the value store is much more low level, allowing one to insert, update and delete immutable or mutable blocks for which an address is generated. Obviously, anyone can decide to use one layer exclusively (and therefore ignore the other one) or to rely on both.
A way to use both layers could be to rely on the key-value store to insert a bootstrap value being the address of a root mutable block and then use exclusively the value store to manipulate the root block which could reference other blocks (mutable and/or immutable). This way, one can benefit from the value store's flexibility while allowing anyone to find the data from a user-defined key i.e through the key-value store.

Talk to us on the Internet!
Ask questions to our team or our contributors, get involved in the project...